前章では,主に国内で実施された学力調査の問題点について説明した。これらの学力調査は,西村らの調査のように調査の設計自体が稚拙なものであったり,刈谷調査のようにその結果の示し方や解釈に問題が見られた。
ただし,いずれの学力調査にも共通する,より根本的な問題は,これらの学力調査が代表性と経年比較の問題を解決できていないことだ。その原因は前章で述べた通り,日本国内には全国の児童・生徒の学力を広範に調査した学力調査の蓄積が存在しないことにある。
この問題点を解決するのが,90年代以降盛んになった大規模国際学力調査である。これらの調査は,国ごとの得点の違いを分析することがその目的の一つであるため,質・量ともに受験者が一国の代表性を確保するのに十分なサンプリングが行われている。また,これらの調査で使われている「項目反応理論」と呼ばれるテスト理論は,各年度におけるテスト結果の経年比較を容易なものにしている。
本章では,こうした大規模国際学力調査,なかんずく,その結果が教育政策に大きな影響を与えたとされるPISA(Programme for International Student Assessment:生徒の学習到達度調査)を例に,学力調査で測定されている「学力」とは一体何を意味しているのか,これらの大規模学力調査で使われている項目反応理論とは一体どういった理論なのか,また,その理論によって何が可能となるのか,という「学力調査のブラックボックス」(Stewart 2013)を説明する。
ただし,本章では学力調査に使われる手法を具体的に説明すると言っても,詳細な説明はもっぱら補遺に示し,本論では簡単な概念的説明にとどめている。そのため,本章の後半で行うPISA調査のデータを用いた分析は若干理解しづらいかもしれない。その場合は都度補遺を参照してほしい。
- 5.1 「学力」とは何か
- 5.1.1 留意点1―調査の実施時点
- 5.1.2 留意点2―学力の規定要因
- 5.2 古典的テスト理論と項目反応理論
- 5.2.1 古典的テスト理論とは何か
- 5.2.2 古典的テスト理論の限界
- 5.2.3 項目反応理論
- 5.2.4 テストの等化
- 5.3 PISA のテスト設計
- 5.4 何が「低下」したのか
- 5.4.1 有意性検定
- 5.4.2 PISAとTIMSSにおいて「低下」した領域
- 5.5 国際学力調査の問題点
- 5.5.1 等化における誤差
- 5.5.1.2 Linking Errorとは何か
- 5.5.2 日本のLinking Error
- 5.6 差異項目機能
- 5.6.1 PISA におけるDIF
- 5.6.2 日本のDIF
- 結語
- 引用・参考文献
5.1 「学力」とは何か
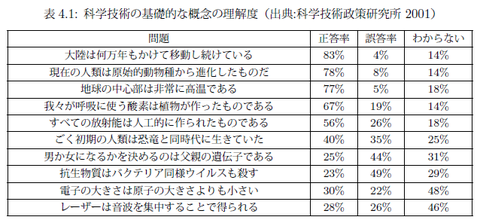
学力調査の結果を正しく解釈するための第一歩は,その学力調査がどのように設計されているのかを知ることである。学力調査の設計は,テストの目的,テストの対象者,測定したい能力,問題項目形式(多肢選択式か自由記述式かなど),実施形態(ペーパーテストかコンピュータ上で行うものか実技か),解答に必要な知識や技能,問題項目の難易度の程度,知識・技能・難易度の組み合わせや配分される問題項目数,制限時間,実施時の環境条件や解答上の注意,など多岐にわたる(日本テスト学会 2010 p.21)。
これらの要素は,いずれもテストの信頼性及び妥当性を保証するために必要な手続きである。そのために,テストの基本設計はテストの内容に関わる専門家だけでなく,テストの専門家による議論によって決定されなければならない。現実にテストを実施する際には上記の諸条件に留意する必要がある。こうしたテストの基本設計(テスト仕様) のうち,特にPISAやTIMSSで理解されていないと思われるのは,「テストが測定したい能力」,つまり「学力」の定義である。
「学力」という概念は,それだけではあまりにも広汎な概念である。そのため,大抵の学力調査では学力という概念の,特定の側面を明らかにすることを目的として実施される。たとえば,学力テストの典型例である大学入学試験においても,センター試験は学習指導要領に示されるカリキュラムの到達度を,個別の大学によって実施される二次試験はその大学に「ふさわしい(大学の講義についていけるか,大学の発展に貢献することができるかなど)」学力を持った受験者を選抜している。
しかし,学力調査の結果が公開され,議論される段階ではこうした学力の定義が問題とされることは殆どない。本来,学力の定義というものは単にテストが測定しようとしている能力を意味するだけでなく,学力という曖昧模糊とした概念を現実に測定することを可能たらしめている,テストの根幹である。学力を定義せずに学力調査を実施することは不可能であり,とりもなおさず,学力の定義を抜きにして学力調査の結果を語ることもできない。
学力は人の身長や体重などと違い,目に見えるものであったり直接測定することができるものではない。こうした「確かに存在していると思われるが,直接的に触れることができないもの」を構成概念と呼ぶ。学力の存在は多くの人が肯定するだろうが,それは目に見える形で実体を伴うものではない。しかし,構成概念がもたらすと思われる実体的な行動を測定し,数値化することで構成概念を間接的に測定することはできる。
たとえば,学力というものは目に見えず,何らかの実体に還元することは(現時点では) 難しいが,学力テストの「点数の違い」の背景には,「学力」という潜在的な概念が存在することは多くの人に想定されているはずだ。この場合,現実のテスト得点が「学力」という構成概念を数値化したものとなる。
ただし,一概に学力といっても,その言葉が意味するところは一意ではない。たとえば,「国語の学力」といっても漢字の習熟度や文章読解能力,表現能力など様々な学力が考えられる。通常のテストでは,測定したい能力をこうしたいくつかの下位概念に分けて,その下位概念を測定する項目に対する得点から学力の分析が行われる。たとえば,数学の学力を測定したい場合,それをいくつかの領域,「量」「空間と図形」「変化と関係」「不確実性」などに分け,それらを測定する問題項目の集合としてテストは作成される。そして,テストの結果は平均点や偏差値などによって代表されることになる。
しかし,構成概念を下位領域に分解しただけでは,学力の定義は十分ではない。学力には知識量であったり,応用能力といったように,異なる次元の学力が考えられるはずだ。たとえば,球の表面積を求めさせる問題では公式を暗記していても解くことができるが,微分・積分の知識を応用して解くこともできる。もし,この二つの学力を違う学力として定義したいならば,それに伴い問題文も変化させなければならない。
或いは,問題が出題される文脈や状況に応じた学力というものも考えられるだろう。たとえば,三角比の値を覚えていれば45度の直角三角形の比が分かる。しかし,水平線から45度の角度に太陽が見えるとき,鉄塔に30mの影ができていても鉄塔の長さは分からないかもしれない。本質的に同じ問題であっても,出題される文脈や状況によって正答率は変化する。
こうした学力の様々な側面を考慮して,測定したい学力が定義される。逆に,単に「学力を測定します」としか言っていない学力調査は,まずまともなものではない。それはつまり,測定する構成概念についての妥当性を検討する作業を行っていないということを意味している。たとえば,TIMSSやPISAでは図5.1,図5.2 のように学力の定義が,或いはその構造が示されている。


TIMSS2003では「数学能力」が測定されているが,「数学能力」はその内容によって「代数」「測定」「数」「幾何」「データ」というさらに小さな領域に分けられている。さらに,それらの内容領域,たとえば「数」という内容領域は,それに関連する領域として「自然数」「分数・小数」「整数」「比率・割合・百分率」といったさらなる下位領域に細分することができる。
したがって,これらの下位領域について問題を作成し,その結果から「数学能力」が数値化されることになるが,TIMSSではさらに,認知的領域として「事実と手順についての知識」「概念の利用」「ルーティン的問題解決」「推論」という4 つの能力も設定している*1。たとえば,「事実と手順についての知識」ならば,単純な四則計算ができるかどうか,数学記号の定義を覚えているかどうか,といったことが問われている。
また,PISA2003で測定されている「数学的リテラシー」は,TIMSSのそれよりも複合的なものとなっている。図5.2では説明の便宜上,「内容領域」「プロセス」「状況」の順に矢印が伸びているが,実際にこの順番で学力が定義されているわけではない。
PISAにおける数学的リテラシーは,特定の内容領域,問題解決のプロセス,問題が出題される状況という三つの側面から学力を定義し,測定している。たとえば,「科学的な状況で出題される不確実性についての熟考」を測定するような問題が,実際のテスト項目として具体化されることになる。
学力の定義という点において,PISAとTIMSSという二つの調査の特徴を挙げると,PISAでは経験主義的な学力を測定しようとしているのに対して,TIMSSでは系統主義的な学力を測定している。たとえば,PISAでは調査の目的が「義務教育修了段階の15歳児が,それまでに身につけてきた知識や技能を,実生活のさまざまな場面で直面する課題に,どの程度活用できるかを測る」とされているのに対して,TIMSSでは「初等中等教育における児童・生徒の算数・数学及び理科の教育到達度を,国際的な尺度によって測定する」とされている。
二つの調査で測定されているものが同じ「数学の学力」であっても,その内容は異なっているということである。実際に,PISAとTIMSSでは,国の順位にはあまり相関がみられない。いずれの調査でも高得点をとっているのは,日本や韓国といった一部のアジア諸国だけである。
5.1.1 留意点1―調査の実施時点
PISAやTIMSSにおける学力の意味内容を確認したところで,この時点で説明できる日本の学力低下に対する留意点を二つ挙げておこう。一つ目の留意点は「(2003年調査以降の)『PISA 受験者』と『ゆとり世代』は同じものではない」ということだ。
前節で確認したように,PISAもTIMSSも義務教育期間,ないしは義務教育修了段階という特定の時点における学力を測定しているに過ぎない。すなわち,PISAやTIMSSの受験者が各国の第4学年,第8学年,或いは15歳児のことを指しているのに対して,「ゆとり世代」は「ゆとり教育を受けた世代」として定義されている。
つまり,PISAやTIMSSにおける成績の落ち込みをそのまま「ゆとり世代」に当てはめてしまうのは,15歳以降の学力変動を全て無視してしまうことになる。1章や2章で確認したように,ゆとり教育における学習内容の削減の多くは,「義務教育段階における一時的な削減」である。仮に,ゆとり教育による学習内容の削減が得点低下の原因だとするならば,義務教育修了以前と以後で学力が変化することは十分に予想できる。
加えて,PISAやTIMSSのように現役の学生を対象に行うテストでは知識の定着や剥落を測定しにくいという面がある。ゆとり教育の目的の一つは,基礎・基本の徹底によって知識の定着を目指すことにあった。仮にこのねらいが達成されていたとしても,PISAやTIMSSの結果からそれを読み取ることは難しい。結果として,義務教育後期ないしは義務教育修了段階では,「ゆとり教育」と「非ゆとり教育」で最も学力差がついているように見える可能性がある。
この仮説を検討できるのが,PISAと同じくOECDが実施した『OECD 国際成人力調査(PIAAC)』である。PIAACは16歳から65歳の成人を対象として,社会生活において成人に求められる能力のうち,読解力,数的思考力,ITを活用した問題解決能力の3分野のスキルの習熟度を測定するとともに,スキルと年齢,学歴,所得等との関連を調査している(文部科学省 2013)。日本においては,平成23年8月から平成24年12月にかけて第1回調査が行われた。
PIAACで測定されている学力,特に読解力に関してはPISAとほぼ同様の定義が行われている。文科省が公開しているPISA2009とPIAAC2012の概要から学力の定義を引用してみよう。
PISA2009:読解力とは「自らの目標を達成し,自らの知識と可能性を発達させ,効果的に社会に参加するために,書かれたテキストを理解し,利用し,熟考し,これに取り組む能力」である。
PIAAC2012:読解力とは「社会に参加し,自らの目標を達成し,自らの知識と可能性を発展させるために,書かれたテキストを理解し,評価し,これに取り組む能力」である。
PISAとPIAACの読解力調査で測定されている学力概念は,ほぼ同一といってよい。また,PIAACでは幅広い年代を対象にして調査を実施しているため,疑似的ながらPISA調査を受験した「ゆとり世代のその後」を追跡調査することができる。加えて,調査対象が成人であり,質問もインターネットを介した対面によるものであることから,無回答率が低く抑えられることも期待できる。PISA やTIMSS を通じて「明らかになった日本の学力低下」の中でも,最も落ち込みが大きかったのはPISA2003・PISA2006 における「読解力の低下」だった。この調査を受験した世代はその後どうなったのか。
表5.1は,PISA調査とPIAAC調査を回帰分析した際の決定係数を示している。多少不正確な説明になるが,決定係数とは,PISA調査の結果がPIAAC調査の結果をどれだけ説明できているかの指標だと思えばいい。決定係数が1ならば,散布図は完全な直線となり,PISA 結果によってPIAACの結果が100%説明できることになる。

まずは,PISA2012とPIAAC調査の決定係数を見てみよう。読解力,数的思考力の決定係数はそれぞれ0.166,0.092とあまり大きくない。子供の学力によって大人の学力を直線的に説明することは難しいということだ。
それでは若年層はどうなっているのか。表5.1の2行目から5行目は,PISA2000からPISA2009の4回のPISA調査を受験したそれぞれの世代の結果と,その世代のPIAAC調査における結果の決定係数を計算している。
こちらでは,決定係数の値は先ほどよりも大分大きくなる。PISA調査が実施されるのは義務教育修了段階なので,これは義務教育段階の学力が,10代後半から20代の若年層の学力に一定の影響を与えていることを示唆している。
また,受験者の年齢が上がるにつれて決定係数が小さくなっていくという傾向も見られる。つまり,義務教育修了段階の学力の影響は,年齢を下るにつれて小さくなっていくということである。
それでは実際に,それぞれの世代が受験したPISAとPIAACの結果がどのように関係しているのかを見てみよう。図5.3から図5.6はPISA2000からPISA2009の結果と,そのPISA調査を受験した世代のPIACCの結果の散布図である。横軸にPIAAC調査の得点を,縦軸にPISA調査の得点をとっている。いずれの世代においても,日本はPISA調査と比較して,PIAACでは相対的に順位を上げている傾向が確認できる。




そうした傾向が一層鮮明に見られるのは,PISA 調査において「著しい読解力の低下」が見られたPISA2003,PISA2006を受験した世代である。PISA2003では,日本の読解力は14位(統計的に有意差がないのは9~16 位),PISA2006では15位(統計的に有意差がないのは10~18位) であった。しかし,PIAAC調査を受験したPISA2003,PISA2006年世代は,いずれもフィンランドに次ぐ2位であり,1位のフィンランドとはどちらも有意差がない(p > .05)。
また,この傾向は「数的思考力」についても同じことがいえる*2。数的思考力について,日本のPIACC調査の順位は,PISA2000世代から順に,2位(26~28歳),3位(23~25歳),2位(20~22歳),5位(17~19歳) となっているが,いずれも1位の国と有意差はない(p > .05)。
もちろん,PISAとPIAACでは構成概念が類似しているといっても,両者の間で同一の問題が出題されているわけではない。したがって,両者の結果を等化することは原理的に不可能である。特に,PISA調査の数学的リテラシーとPIAAC調査の数的思考力はほぼ別物と言ってよい。
しかしながら,PISAとPIAACの比較調査では「学校卒業後の学習経験が学力に大きな影響を与えること」が示唆されていること,そして実際に,「PISA 調査で読解力が低下していた世代も,PIAAC では1 位グループとなっていること」,この点は留意しておくべきだろう。
(補足:横軸を揃えてないので分かりづらいが,各世代の読解力得点はPISA2000>PISA2003>PISA2006>PIS2009となっており、年齢と供に得点が上昇するという順当な結果となっている。世代間の得点差を見てもPISA2003・PISA2006世代での大きな読解力低下は見られない)
5.1.2 留意点2―学力の規定要因
もう一つの留意点は,学力の規定要因についてである。ゆとり言説においては,学力低下の原因といえばすなわちゆとり教育であり,その他の議論が考慮されることは殆どない。しかし,当たり前のことではあるが,学力を規定するのは学校教育だけではない。
子どもの学力には,親の学歴,職業,年収,或いは生徒の性別,年齢,居住地,或いは,学習塾や図書館,学習センターの数など様々な社会的・経済的・文化的要因が規定要因として考えられる。2000年代以降これらの要因が全く変化していないことなどあり得ない。
実は,PISAやTIMSSといった大規模な学力調査は,単に子どもに対して学力テストを解かせているだけではない。その子どもが置かれている社会的・経済的・文化的環境に対して(もちろん学校の環境に対しても) 質問紙調査を実施することで,何がその国において学力の規定要因となっているのかを明らかにすることを目的の一つとしている。
特に,PISA調査では「アセスメント」,つまり,能力の到達度はかることよりも,それを多面的に評価することに主眼を置いている。前節で見たように,PISAにおける学力は社会生活と密接に結びついている。子どもの生活条件が考慮されるのは必然だろう。
「学力低下」の議論にしろ,「学力格差」の議論にしろ,ゆとり教育言説の流行は学力を複数の要因から多角的に議論する視座を失わせてしまった。学力が低下したという結果が出ればすぐさま教育制度の変更に飛びつき,学力格差が増大したという結果が出れば国のエリート教育,落ちこぼれ切り捨ての結果(或いは愚民政策とも)だと騒がれる。そして国も世論に右往左往して,一貫した教育政策などはとても望める状況ではない。
(以下省略)
5.2 古典的テスト理論と項目反応理論
大抵のゆとり言説では,PISAやTIMSSにおける学力の意味は無視されている。しかし,より一層深刻なのはこれらの調査で採用されている設計・分析手法に対する無理解である。そこで本節では,テストを運用する際の背景理論となる「テスト理論」について説明する。テスト理論には主に,古典的テスト理論と呼ばれるものと項目反応理論と呼ばれるものの二つが存在する。
5.2.1 古典的テスト理論とは何か
古典的テスト理論によって運用されているテストを一言で言えば,われわれが日常的に受けているテストそのものである。つまり,全ての受験者が同一の問題を一斉に解き,その結果として得られたテスト得点から平均値や偏差値,識別力といったものが計算される。また,それらの統計量から,テストの性質や受験者の能力,テスト項目の特性などが分析される。多くの人にとってはお馴染みのテスト形式であり,教室で行われる小テストから高校・大学の入学試験まで,日本においては基本的に古典的テスト理論によってテストが運用されている。
古典的テスト理論では,テストの平均点と標準偏差から得点の意味付けが行われる。標準偏差とは得点分布の「バラつき」のことである。詳細は補遺に示すとして,ここでは標準偏差の意味を簡単に確認しておこう。たとえば,5人が受験した平均50点のテストがあるとしよう。それぞれの得点は40,45,50,55,60点である。
まず,テストのバラつきの指標としては,個々の得点と平均点の差という統計量が考えられる。これを偏差と呼ぶ。このテストの偏差は-10,-5,0,5,10 となる。しかし,個々の受験者の偏差を足し合わせていっただけではバラつきの指標にはならない。偏差には正負の符号があるため,足し合わせていくと0になってしまうからだ。
そこで,それぞれの偏差を2乗したものを足し合わせることで,そのテストのバラつきを表現することができる。これを偏差平方和と呼ぶ。このテストの偏差平方和は100+25+0+25+100=250 となる。しかし,偏差平方和は受験者の数を増やしただけ大きくなってしまうので,受験者当たりの平均をとらなければならない。このテストの偏差平方和の平均は250/5=50 となり,これがそのテストのバラつきを表現することになる。これを分散と呼ぶ。
しかし,分散は偏差の2乗を使っていたため,その単位も2乗になっている。また値も大きくなっているために,そのままでは直感的にデータのバラつきを把握しにくい。そこで分散の平方根をとったものを標準偏差と呼び,この値がそのテストの平均"的"なバラつきを表現することになる。たとえば,平均が50,分散が50のテストならば,その標準偏差は7.07... となり,そのテストは50点という平均点から平均的に7点程度はばらつくテストだということができる。
この標準偏差を使うことで,あるテストの得点に意味付けを行うことができる。たとえば,平均点は同じ50点だが標準偏差が異なる二つのテストA,Bがあるとしよう。テストAの標準偏差は5,テストBの標準偏差は15である。また,二つのテストを受験した集団は同じとする。このとき,ある受験者がテストAでは60点,テストBでは65点をとった。果たしてどちらのテストの方が「良い成績」だったのだろうか。
それを判断するためには,二つのテストの尺度を同じにしてやればいい。それぞれのテスト得点から,その平均点を引き,標準偏差で割れば二つのテストの尺度は一致する。これを標準化と呼ぶ。標準化の理屈は,平均値と標準偏差の計算式から容易に理解できる。まず,平均点を引くという作業はそのテストの平均点を0に調整する作業だ。平均が50点であるテストにおいて個々の受験者の得点から50を引けば,そのテストの平均点は当然0になる。次に,それを標準偏差で割るというのは,そのテストの標準偏差を1に調整する作業である。
もう一度,標準偏差の計算式を思い出してみよう。あるテストの個々の得点にαを掛けると,そのテストの平均点はα倍される。個々の得点もα倍されているのだから,その偏差もまたα倍されている。分散は偏差の2乗を使っていたのだからα^2倍,標準偏差はその平方根なのだからα倍である。つまり,個々のテスト得点をα倍するということは,そのテストの標準偏差をα倍するということだ。したがって,あるテストを,そのテストの標準偏差で割ってやれば,そのテストの標準偏差は1になる。
これで,二つのテストを平均が0,標準偏差が1という同一の尺度上で表現できるようになった。これを標準化と呼ぶ。なおテスト得点の分布が正規分布している場合,正規分布の形状と位置は平均と標準偏差という二つのパラメータによってのみ決定されるので,二つのテスト得点の分布は完全に一致することになる。テスト得点は必ずしも正規分布するわけではないし,また正規分布でなければ標準化に意味がないというわけでもないが,実際のテスト得点は正規分布に近似されることが多いので,以降の説明もテスト得点は正規分布していることを仮定する。
それでは,テストAにおける60点と,テストBにおける65点という得点を標準化しよう。テストA の標準偏差は5だったので,60点を標準化した得点は(60-50)/5=2点である。また,テストBの標準偏差は15だったので,65点を標準化した得点は(65-50)/15=1点である。したがって,テストBで65点だったことよりも,テストAで60点だったことをこの受験者は喜ぶべきだろう。標準化した得点が1点ならば,その受験者は上位16%に位置しているが,標準化した得点が2点ならば上位2%に位置していることになる。
5.2.2 古典的テスト理論の限界
こうして標準化された得点などを用いてテストの結果は解釈される。二つのテストの平均値が同じでも,標準偏差の違いによって標準化された得点は異なるし,平均値より上,或いは下の得点だったとしても標準偏差が大きければ,平均値との実質的な差はないかもしれない。標準得点さえわかれば同一の受験者が異なるテストを解いた場合でも,異なる集団が同一のテストを解いた場合でも,テストの結果を有意味に解釈することができる。
しかし,古典的テスト理論によるテスト得点,或いはテスト項目に対する意味付けには理論的な限界が存在する。それは受験者の性質とテストの性質が分離できないことだ。素点や偏差値,或いは通過率や識別力といった古典的テスト理論による分析は,受験者集団の特性分布と項目の特性の双方に依存している。これを学力の比較という観点から考えるならば,二つの集団に異なるテストを与えた場合,テスト得点の変化が受験者集団の変化に起因しているのか,テスト項目の変化に起因しているのかが原理的に区別できないということだ。
したがって,古典的テスト理論において得点の意味付けが可能となるのは,同一の受験者集団が異なるテストを解いた場合,異なる受験者集団が同一のテストを解いた場合,同一の受験者が同一のテストを解いた場合に限られてしまうのである。
これが,通常のテストにおいて経年比較が難しくなってしまう大きな理由である。異なる年度で異なる受験者が解いたテストの結果を比較可能なものにするには,テストを同一の問題にしなければならない。そのためにはテスト問題を秘匿する必要がある。しかし,テスト問題を完全に秘匿するのは現実的には難しい。
第一に,受験者は当然にそのテスト項目を知っているのだから,彼らの口をふさぐ何らかの手段を用意しなければならない。少数の集団であれば口頭での注意で足りるかもしれないが,大規模な学力調査ではまず不可能である。
第二に,一部の問題が漏えいしても,出題者側にどの問題が流出したか知られていなければ対策をとることも難しい。また,漏えいした問題を特定してテストから除外しても,それを繰り返せばテストの項目プールは早々に尽きてしまう。
第三に,日本ではテスト(特に学生を対象とするテスト) は,学習のフィードバックのために利用されることが多い。たとえば,センター試験の問題は毎年新聞にも掲載され,受験生はその公開されたテストを利用して学習を進めている。いわゆる「過去問」の利用である。そのため,テスト項目を秘匿することは教育目的から反発されることもある。
5.2.3 項目反応理論
この古典的テスト理論の限界を克服するのが項目反応理論(Item Response Theory=IRT) である。IRT では「異なる受験者が異なるテストを受験した場合」でも,両者のテスト得点を比較することが可能になる。直感的には不可能だとしか思えない。なぜそうした比較がIRT では可能になるのだろうか。本節ではそれを説明しよう。なお,ここで説明するのは項目反応理論の概要である。IRT モデルの導出,母数の推定,母数の等化などについては補遺を参照されたい。
まずは,項目反応理論と古典的テスト理論の概念図を示そう。図5.7がそれである。

古典的テスト理論では,「受験者の性質」と「項目の性質」が混在した「テスト項目への反応」,或いはその総和としての「テストの結果」を受験者の能力や項目の性質の尺度値としていた。この場合は,受験者か項目のどちらかを固定しなければ,その尺度値を比較することはできない。これが古典的テスト理論の限界である。
しかし,項目反応理論では,受験者の項目への反応を手掛かりにして,受験者が持っている目に見えない「学力」という概念をより直接的に測定しようとする。そして受験者の潜在的な学力(潜在特性) と,その正答率から項目の性質も決定されることになる。言葉だけではわかりにくいと思うので,図で示してみよう。図5.8は項目特性曲線(Item Characteristic Curve=ICC) と呼ばれるものである。

ICCのグラフでは横軸に受験者の潜在特性(学力) を,縦軸に正答確率を配している。項目の性質はこのICCによって記述されることになる。ICCは受験者の潜在特性が高くなるにつれて,右肩上がりに正答確率が高くなっていく。また,難しい項目であればICCは右にずれ,易しい項目であれば左にずれる。それが項目特性(困難度) の違いということだ。ここでは,全てのICCの傾きが同じになっているが,これは1母数モデル(ラッシュモデル,1PLモデル) と呼ばれる確率モデルの場合である。
1母数モデルというのは,項目の困難度というパラメータだけを使ったモデルということだ。潜在特性の値によって項目の性質が変化するような場合*3には識別力というパラメータが使われるし,偶然の正答を考慮したい場合は当て推量パラメータが使われる。それぞれICCの傾きと切片のようなものである。しかし,ここでは説明を簡単にするため,また本稿で分析するPISA調査ではラッシュモデルという1母数モデルが使われているため,1母数モデルを例にしてIRTを説明する。
図5.8のICCで注目してほしいのは,横軸が受験者の潜在特性となっていることだ。ここで疑問に思う人もいるかもしれない。そもそも項目反応理論における潜在特性と,古典的テスト理論におけるテストの得点は何が違うのだろうか。どちらも,受験者の学力を数値化したものであるのは変わらないように思える。しかし,受験者の潜在的な学力の分布と,その受験者のテスト得点の分布は根本的に異なったものだ。たとえば,受験者の潜在特性が正規分布だとしても,テスト得点が正規分布するとは限らないし,潜在特性が正規分布ではないとしても,テスト得点は正規分布することがある。
つまり,テスト得点の分布は,そのテストが測定しようとしている「学力」の分布とは異なるものであるということだ。この二つを混同している人は多い。こちらの記事ではセンター試験を例にした簡単なシミュレーションを示しておいた。その結果からは,学力が正規分布している集団の「下位集団」「中位集団」「上位集団」,いずれにおいても,その得点分布が正規分布に近づいている事を確認できる。
さて,項目反応理論では,受験者の項目に対する反応から受験者の潜在特性を推定しているため,受験者の能力が項目の困難度と混ざってしまうことがない。それでは,受験者の潜在特性はどうやって推定しているのだろうか。受験者の潜在的な学力といっても,それだけではつかみどころがない。何らかの仮定,或いはモデルを考える必要がある。それこそがICCなのである。
ICCとは要するに,(条件付き) 正答確率を受験者能力の関数として表現したものだ。そしてIRTでは,標準正規分布の累積分布関数をICCとして利用している。さらに,それをロジスティック関数を利用して近似したもの
これがIRTではICCとして利用される*4。なお,は受験者の潜在特性であり,
は項目の困難度である。また,
とはネイピア数
の
乗という意味だ。ここでは深く考える必要はない。要は,この式こそが図5.8のICCであり,IRTにおける確率モデルだということだ。たとえば,受験者の潜在特性を1として,その受験者が困難度0の問題を解くならば,その正答確率は
,
を上式に代入して0.7310586......と具体的に計算することができる。
そして,が大きくなればICCは右にずれるし,小さくなれば左にずれることになる。1母数モデルの場合は困難度
によってのみ,つまり曲線の平行移動によってのみICCは変化する。また,この式からは項目困難度の定義も導くことができる。たとえば,項目の困難度が1であるというのは何を意味するだろうか。注目してほしいのは,
の式では潜在特性と困難度の差によってのみ正答確率が表現されているところだ。
の場合でも,
の場合でもその正答確率は変わらないのである。そして,
のとき,その正答確率は必ず0.5になる。
つまり,項目困難度が1であるというのは,その項目を五分五分の確率で解ける受験者の潜在特性が1であるという意味なのである。そのため,項目困難度と潜在特性の単位は一致し,直感的な解釈が可能となる。なお,のときに,
になるのは,識別力パラメータを使う2母数モデルでも変わらない。識別力を使う場合は
式の
の部分に識別力パラメータをかけるだけだからだ。
さて,今,ICCによって,潜在特性と困難度の二つの値が分かれば,その項目の正答確率を導けるようになった。ここまでくれば,潜在特性と困難度を推定することができる。たとえば,ある受験者が全4問のテストに対し,]という反応をしたとしよう。ただし1は正答を,0は誤答を意味している。また,この4問の項目困難度が全て0だったとしよう。そうすると,項目困難度の値と
式を使うことで,
]というパターンが観測される確率を計算することができる。つまり,
と書くことができる。
潜在特性の推定とは,この式が最も大きくなるように,言い換えれば]というパターンが最も観測されやすい
を見つけることである。たとえば,
のとき
]というパターンが観測される確率は
なので,0.475^2・0.525^2=0.062となる。また,のときも同様に0.062となる。そして,察しているかもしれないが,項目困難度が0である4つのテスト項目に,
]という「五分の」反応を最も高い確率で返すのは
のときであり,この時の確率は6.25%となる。したがって受験者の潜在特性は0と推定されるのである。
通常のテストでは受験者の母数も,項目の母数もわかっていないことがほとんどなので,上記の計算ほど単純ではないが,その場合はと
についてそれぞれ偏微分して0とおいた方程式を解くだけである。
5.2.4 テストの等化
ここまでの説明では何やら狐につままれたような気持になるかもしれない。本来は数値化されていない学力という概念がどうして0になったり,1になったりするのだろうか。この数字には一体どんな意味があるのか。
もちろん意味などない。前節ではたまたま潜在特性が0となったが,この数字自体に実質的な意味が込められているわけではない。ICCとして利用する関数を変えても推定値の値は変化するし,受験者集団の学力分布が変化しても,やはり推定値は変化する。より学力の高い集団がテストを解けば,項目困難度はより低く推定されるだろうし,より学力の低い集団がテストを解けば,項目困難度はより高く推定されることになる。
それでは古典的テスト理論と同じではないかと思われるかもしれないが,そうはならない。 式をもう一度見てほしい。ある受験者のある項目に対する正答確率は,その受験者の潜在特性
とその項目の困難度
の差によって決定されていた。そうすると,
の値をそれぞれ
と表現しても
式による正答確率は変化しないことになる。つまり,ICCは項目によって一意に決定されるのではなく,任意に平行移動することができるのである。あるテストに割り当てられた尺度は「仮の」尺度であり,その尺度を変換しても確率モデルの値は変化しない。
この性質が,二つの異なるテストを等化する上で決定的に有用な性質となる。少し抽象的で不正確な物言いをすれば,受験者の潜在特性や項目の特性は,それ自体として「本質的で普遍的な量」を持っているはずである。仮にそれをとすれば,学力の高い集団が解いても,低い集団が解いても,項目困難度は
のままで変わらないし,また,難しい項目を解いても,易しい項目を解いても,受験者の潜在特性は
のままで変わらないはずである。
したがって,ある共通の問題,或いは共通の受験者の母数に二通りの値が計算されたとするならば,その違いは単なる「見た目」の違いであり,本質的には同じものであるはずだ。つまり,二通りの母数について共通の尺度を与えることができれば,その値は一致するはずである。これがIRTにおける等化の原理だ。たとえば,図5.9は集団AにテストA(項目1,項目3,項目4) を,集団BにテストB(項目2,項目3,項目5) を与えたときのICCである。

ここで注目するのは,テストAとテストBで共通項目となっている項目3だ。項目3の困難度は,集団Aでは-1.0,集団Bでは1.0となっている。しかし,項目3の困難度は本来は同じものであるはずだ。また,1母数モデルの場合,尺度を変換したときのICCの移動は平行移動だけが許されていた。そこで,テストBの項目困難度からそれぞれ2を引けば,テストAとテストBにおける項目3のICCは一致し,項目2の困難度はテストAの尺度上で困難度-1.5,同様に項目5の困難度はテストAの尺度上で0と表現できる。ここで等化に使った-2という値は潜在特性にも同様に使うことができる。テストBで=1.0だった受験者もテストAの尺度では
=−1.0となるのである。
つまり,二つの異なるテストの間に,共通の項目,或いは共通の受験者が一部でも含まれていれば,それを手掛かりにして二つのテストを等化することが可能になるのである。前者を共通項目デザイン,後者を共通受験者デザインと呼び,PISAやTIMSSなどの大規模学力調査では大抵,共通項目デザインによってテストが運用されている。
5.3 PISA のテスト設計
「異なる受験者が異なるテストを解いた場合」でも,テストの等化が可能になるというIRTの性質は,PISAやTIMSSなどの広範な学力を測定する大規模学力調査においては極めて有用である。
測定する学力が広汎なものであるほど,それを測定するテスト項目も膨大なものになる。PISAでは,その年の主要分野となる領域の問題は100問以上が出題され,その他2分野と合わせた問題数は200問近くになる。また,TIMSSでも数学(算数)・理科のそれぞれで200問ほどが出題されている。合計400問だ。これだけの問題数を全ての受験生に解かせるのは現実的には不可能である。そこで,PISA やTIMSS といった大規模学力調査では「重複テスト分冊法」と呼ばれる手法が使われている。
重複テスト分冊法では,テストで使われる全ての問題をいくつかのブックレットに分割し,そのブックレットのいずれか1冊を受験者は解くことになる。それぞれのブックレットに含まれる問題は,少なくとも1回以上は共通項目として別のブックレットにも現れる。このブックレット間の共通項目を利用して,全ての問題に対し等化が可能となる。たとえば,表5.2はPISA2003におけるブックレットデザインの例である。

PISA2003では,全ての領域を合わせて167問が出題されているが,それらの問題は分野ごとにいくつかのクラスターにまとめられている。上の表のM,S,R,PS はそれぞれ,数学的リテラシー(Mathmatics literacy),科学的リテラシー(Science literacy),読解力(Reading literacy),問題解決能力(Ploblem Solving) の四つの分野を意味している。PISA2003では,数学的リテラシーが主要分野(main domain) であったため,数学的リテラシーは七つのクラスター(M1~M7) にまとめられ,その他の分野はそれぞれ二つずつのクラスターに(R1,R2 など) にまとめられている。
各受験者は,この13冊のブックレットの内,いずれか1冊のみを選択し受験することになる。こうすることで,生徒・学校側の負担を少なくしたうえで,より多くの項目を実施することが可能となる。
ただし,この実施形態からわかるように,重複テスト分冊法を用いたテストは集団の能力を推定することに重点を置いている。個々の受験者はテスト全体の半分も解いていないか,場合によっては全く解いていない*5。そのため,個人のテスト結果をそのまま個人の能力の推定値と見なすには誤差が大きくなってしまう。
加えて,PISAやTIMSSでは受験者能力の推定値としてPVs(Plausible Values) というものを利用している。これは,受験者の「ありうる能力の分布」から,受験者の能力値をランダムドローした値だ。こうすることで集団の能力値をよりよく推定できるのである。そのため,各受験者に割り当てられるPVsは,その受験者の能力値を意味してはいないことに注意しなければならない。
また,単純に平均正答率を比較することにも注意が必要である。もともと,PISAやTIMSSは平均正答率で比較することを前提に設計されているわけではないからだ。たとえば,重複テスト分冊法を利用したテストの場合,ブックレット効果と呼ばれるものが存在する。特定のブックレットがより簡単に,或いはより難しくなってしまう現象である。IRT を利用したテスト得点はこのブックレット効果を考慮して計算されるが,平均正答率の計算では考慮されていない。他にも,部分点や無回答の扱い方など様々な点において,PISAやTIMSSで計算されるテスト得点と平均正答率は異なった性質を持っている。詳細はPISAの報告書(OECD 2014a p.148) などを参照してほしい。
もともとPISAやTIMSSはIRTを前提としてテストを設計している。一方,正答数や正答率を学力の指標とするのは,古典的テスト理論の話である。古典的テスト理論の場合は,同一の問題を同一の形式で,全ての受験者に解かせるのだから,正答率を比較することにも意味がある。が,PISAやTIMSSは古典的テスト理論で運用されているわけではない。テストの結果を正しく解釈したいならば,まずはそのテストが依拠しているテスト理論を理解しておかなければならない。
5.4 何が「低下」したのか
5.4.1 有意性検定
それでは,PISAやTIMSSではどういった指標を使って学力の変化を論じているのだろうか。もちろん,その一つには「テストの得点」が挙げられる。たとえば,PISA2000における日本の読解力得点は平均522点,PISA2003なら平均498点である。ただし,PISAやTIMSSにおけるテスト得点は,古典的テスト理論のように単なる正答数の総和ではない。これらの点数は,推定された受験者の潜在特性を標準偏差が100,平均が500となるように調整したものだ*6。そのため,これらのテスト得点こそがPISAやTIMSSにおける「学力」の指標ということになる。
それでは,このテスト得点をどのように比較したらいいのだろうか。単に数字の大小だけで学力の変化を議論することができるのだろうか。おそらく,多くの人は「有意差」という言葉を一度は聞いたことがあるはずだ。しかし,その言葉の意味するところを正確に理解している人は少ないかもしれない。そこで本節では,「学力低下」を論じる前に,点数の変化が何をもって有意と表現しうるのかを確認しておこう。ただし,本節の説明も詳細は補遺に示し,ここでは検定の考え方について簡単に触れるにとどめる。
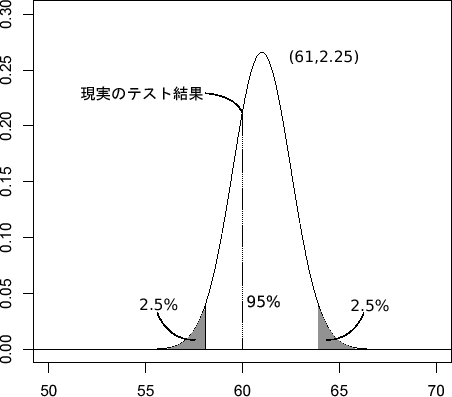
「二つの集団の平均点に差はある・ない」といった仮説を検証する作業を「検定」と呼ぶ。それが統計学の手法によって行われるならば,統計的仮説検定や統計学的検定などと呼ばれることになる。ここで重要なのは,「差がある・ない」といった命題が確率の基準によって判断されるということだ。たとえば,ある仮説が正しいと仮定した場合に,その仮定のもとで導かれる確率的モデルと現実のデータの間に不整合が見られる場合には,その仮説を棄却するという判断が合理的と言える。これが統計学的仮説検定の考え方である。この説明では回りくどく感じると思うので,実際のPISA平均点を使った図で簡単に説明してみよう。

図5.10は,PISA2000の読解力平均点の分布とPISA2003の読解力平均の分布,PISA2000とPISA2003の平均点の差の分布である。括弧の中はそれぞれの分布の平均と標準偏差*7である。
「平均点の分布」とは何ぞや,と思われるかもしれない。現実に得られた平均点はそれぞれ522点と498点という一つの値だ。しかし,何事にも誤差というものはつきものである。もし,「真の平均点」というものが存在するならば,現実に得られる得点は「真の平均点+誤差」という形になっているはずだ。図5.10の分布はこの真の平均+誤差の分布なのである。3.9,5.2という値は真の平均から3.9点,5.2点程度は平均的に誤差が生じることを意味している。ただし,真の平均である
と
を便宜上522点と498点としてグラフを描いているが,実際の真の平均は未知である。
平均点が一定の誤差をもってバラつくならば,平均点の差の分布はどうなるのだろうか。実は,ある統計量が正規分布に従うとき,その平均の和と差も正規分布に従うことがわかっている。しかも,その標準偏差はという非常にわかりやすい形となる。もちろん,平均は二つの統計量の和ないしは差である。したがって,PISA2000とPISA2003の平均点の差は平均が
,標準偏差が
の正規分布に従うことになる。
ここからが具体的な検定の手順となる。まず,検定を行うには検定するべき仮説を立てなければならない。この仮説には通常,「PISA2000 とPISA2003 の『真の』平均点には差がない」といったように,差がない,或いは効果がないといった仮説を立てる*8。これを帰無仮説と呼び,それとは反対の仮説,「PISA2000 とPISA2003 の『真の』平均点には差がある」という仮説を対立仮説と呼ぶ。多くの調査では,複数のデータに何らかの差があること,つまりは対立仮説を実証するために行われている。それにも関わらず,こうした回りくどい仮説を立てるのは,対立仮説は無数に存在するため,どの対立仮説を検定すればいいのかがわからないからだ。
検定とは,この帰無仮説が正しいと仮定した場合の「平均点の差の分布」に対して,現実に得られた「24点」というデータがどの程度起こりにくいのかを確率的に評価し,その結果によって帰無仮説を棄却するのか,しないのかを判断するプロセスなのである。まず,平均点の差を として,それを標準化しよう。平均点の差という統計量の平均は
,標準偏差は6.5である。しがって,その標準化量は
となる。標準化しているのだから,この統計量は平均0±1の間に約68%,±2の間に約95%の値が含まれることになる。これは確率と読み替えてもいいだろう。68%の確率で±1の範囲に,95%の確率で±2の範囲に含まれるということだ。重要なのはここからである。もし,「PISA2000とPISA2003の平均に差はない」という帰無仮説が正しいならば,=0となる。図5.10で言えば右側の二つのグラフが同じ平均点を軸として重なり合っているということだ。したがって,
の式は
という単純な式になる。
これに現実の平均点差である24点をいれると,24/6.5≒3.7となる。この得点は標準化されているので,これ以上に極端な点差がでる確率は0.02%程度である。つまり,帰無仮説が正しいという仮定の下では,24点という点差は非常に起こりにくいものと判断せざるを得ない。
したがって,「平均点に差はない」という帰無仮説は棄却され,このとき「平均点の差には有意な差がある」と表現されるのである。ただし,注意してほしいのは,0.02%という確率は帰無仮説が正しい確率ではないし,99.98%というのは対立仮説が正しい確率でもないということだ。
また,0.02%という数字は差の大きさを表しているわけではないということにも注意してほしい。仮に,この確率が0.00001%だったとしても,それだけでは差の大きさを知ることはできない。実際にはほんのわずかな差であるかもしれないし,逆にとてつもなく大きな差であるかもしれない。ここで計算した0.02%という数字のように「現実に得られたデータ以上に極端な値が出る確率」を一般にp値と呼ぶが,p値の解釈については以下のASA声明を参照してほしい。
5.4.2 PISAとTIMSSにおいて「低下」した領域
こうした手続きを経て,「学力の変化は統計学的に見て有意である」と言うことができるのである。それでは実際に,PISAとTIMSSではどの領域が低下したのかを確認しよう。何度か述べたように,PISAやTIMSSにおける「学力」は融通無碍に語られている。そこでは調査における学力の定義が無視されるどころか,時として「数学」「理科」といった領域の枠すら無視されることがある。しかし,PISAやTIMSSでは,全ての領域において学力低下が見られたわけではない。本節はまずそのことを確認しよう。
ただし,その前にPISA調査については補足しなければならないことがある。PISAでは各年度の調査ごとに,重点的に調査される主要分野(main domain) が切り替わっているが,経年比較が可能となるのは,その分野が主要分野となった後のことである。たとえば,PISA2000では読解力が主要分野となっているため,以降の調査は全て相互に比較可能となっているが,数学的リテラシーが主要分野となったのは2003年調査,科学的リテラシーが主要分野となったのは2006年のことであるので,それ以前との比較はできない。
なぜそうなるのかと言えば,PISAにおける主要分野はその後の調査における基準としての役割を果たすからである。たとえば,PISAでは平均が500,標準偏差が100となるように点数が調整されているが,この点数はその分野が初めて主要分野となった調査に限られる。つまり,正確に平均が500,標準偏差が100となっているのは,PISA2000の読解力,PISA2003の数学的リテラシー,PISA2006の科学的リテラシーのみであり,その他の分野は,この基準から平均,標準偏差が計算される。したがって,主要分野となる前の年度と比較をする場合,報告書の数値をそのまま使うことはできない。
また,調査の主要分野となった領域はその後の経年比較に耐えうるように,テストの枠組みやテストデザインが慎重に設計されることになる。逆に言えば,主要分野となる前のテストはいわば予備調査であり,調査の枠組みが十分に開発されておらず,後にテストデザインが変更されることもある。たとえば,数学的リテラシーは2003年に主要分野となり,「量」「空間と図形」「変化と領域」「不確実性」の4領域が調査され,以後の調査も同様であるが,PISA2000では「空間と図形」「変化と関係」の2領域しか調査されていない。これらの理由から,主要領域となる前の結果を直接的に比較することはできない。そのためPISAの報告書でも,後述する「Linking Error」は主要分野となった年とそれ以降の調査のものしか報告されていない。
これらのことを考慮して,PISA・TIMSSで日本の点数が有意に変化したものをまとめると以下の図のようになる。ただし,有意水準は0.05である。つまり,標準化した検定統計量が
の範囲を満たさないとき,「有意差がある」と判断されることになる。 また,PISAの検定は得点の標準誤差としてLinking Errorというものを使うため,単純な平均点の差の検定結果とは異なっている。
(これを書いていた当時はPISA2018・TIMSS2019の結果が発表されていなかったため、最新年度を含むPISA・TIMSSの検定結果はそれぞれ以下の記事を参照してほしい)
一般に思われているように,PISAやTIMSSでは全ての領域で学力が低下したことを実証したものではない。まずは,科学的リテラシーないしは理科を見てみよう。おそらく,ゆとり教育で最も影響を受けたのは理科教科だろう。ゆとり教育で削減された学習内容の削減が一時的なものであることは2章でも述べたが,理科については高校での教科選択によって,削減された内容がそのままになってしまう可能性がある。98年改訂でも,高校に「理科基礎」「理科総合A」「理科総合B」という中学程度の生物・物理・化学をまとめた教科が必修として存在しているが,一部の高校では受験対策のためにこれらの教科を履修していない可能性がある。
そのため,もし中学校段階で学力低下が見られるとすれば,その学力低下は高校に上がっても解消されない可能性がある。それでは,PISAとTIMSSではゆとり教育が始まってから,理科の学力は低下したのだろうか。表5.6,表5.9を見る限り,PISA・TIMSSともに中学校段階での学力低下は確認できない。TIMSSでは小学校4年で2003年と2007年の点数が有意に低下しているものの,中学2年生のTIMSS2007,TIMSS2011では有意な点数の変化はない。TIMSSが小学4年生と中学2年生の成績を4年ごとに調査しているのは,小学4年生の学力を追跡調査するためでもある。つまり,TIMSS2003,TIMSS2007 で有意に点数が低下した小学生も,彼らが中学2年生になった4年後には有意な点数の変化がなくなっているということである。
しかし,PISA調査ではPISA2003以前との比較ができないので,学力低下論者からすれば納得できないかもしれない。PISA2000とPISA2003の比較に限ればLinkingErrorが計算されているので,念のため検定を行っておこう。PISA2000の平均点は550点,PISA2003の平均点は548点,それぞれの標準誤差は5.5,4.1,Linking Errorは3.112 である(ただし全てPISA2000を基準とした尺度)。検定統計量は0.266であり,有意差はない。
なお,先ほど述べたようにPISA2006では科学的リテラシーが主要分野となったため,PISA2000,PISA2003との比較はできないが,PISA2003との暫定的(interim) なLinking Errorは報告されているので,計算自体は可能である。PISA2006における日本の科学的リテラシー得点はロジットスケールで0.512,PISA2000のスケールに変換すると525点である。計算方法については,"PISA 2006 Technical Report",pp246-247 を参照のこと。
しかし,PISA2006では出題領域が大きく拡大されているため,PISA2003とPISA2006の共通スケールは,二つの調査の共通項目に基づいてのみ計算されている(OECD 2009 p.246)。PISA2003とPISA2006の共通項目22問のみから計算される得点は,PISA2003では547点,PISA2006では548点(OECD 2007 pp.369-370),それぞれの標準誤差は4.4,4.1,Linking Errorは4.963 である。検定統計量は-0.128であり,有意差はない。なお,PISA2000とのLinking Errorは暫定的な値も報告されていないため比較はできない。
次に数学的リテラシーないしは数学を見てみよう。TIMSSでは理科の傾向とは反対に,小学校では有意な点数の変化が見られないものの,中学校ではTIMSS2003以降に有意な点数の低下が見られる。また,PISAでは,2003年から2006年にかけて有意な低下が見られるが,PISA2012では有意な点数の上昇となっている。こちらも念のためPISA2000とPISA2003の検定を行っておこう。「空間と形」では,PISA2000 の平均点が565点,PISA2003の平均点は553 点,それぞれの標準誤差は5.1,4.3,Linking Errorは6.008である(ただし全てPISA2003を基準とした尺度)。検定統計量は1.34であり,有意差はない。また,「変化と関係」では,PISA2000の平均点が536点,PISA2003の平均点も536点である。PISA2000の得点はPISA2003の尺度上の数値なので,検定する必要もないだろう。有意差はない。なお,PISA2006以降の調査とPISA2000調査とのLinkingErrorは報告されていない。
最後に読解力を見ていこう。なお,TIMSSを実施しているIEAは読解力調査としてPIRLSという調査を実施しているが,日本は参加していないため,読解力の変化を議論できるのはPISA調査だけである。これまでにも何度か言及したが,PISAやTIMSSにおいて最もインパクトのある「学力低下」は読解力の低下である。PISA2003では参加国32か国のうち,10ヵ国で読解力得点の低下が見られたが,日本の24点という低下はその中でも最も大きなものだった。また,2006年調査でも読解力得点は上がらず,日本の読解力得点はOECD平均と同じ水準になっている。しかし,PISA2009,PISA2012では読解力の大幅な向上が見られ,PISA2000と同程度の水準となっている。
本章の冒頭で,PISAやTIMSSの結果には一定の留保をつける必要があると述べた。そうした留意点については今までにもいくつか述べてきたが,以降の節では特に「PISA調査における著しい読解力の低下」に焦点をあてて具体的な分析を行っていきたい。日本の読解力の変化はPISA調査の中でも特異なものとなっているため,PISA調査の設計者を含む何人かの研究者からも,この現象についていくつかの指摘がなされている。本章ではそれを具体的に確かめてみようという趣旨である。
ただし,PISA2000とPISA2003の比較において,多くの国で有意な読解力得点の変化が起こったことについて注意が必要であることは,そもそもPISAの報告書でも言及されている。PISA2009の報告書ではこの「不安定性」の原因として,テスト項目の出題順が変更されたこと,問題ユニットからいくつかの項目が削除されたこと,PISA2000の問題クラスターから新しい問題クラスターが作られたことなどを挙げている。これらの変更はすべて項目母数の推定にも影響を与える。したがって,PISA2000とPISA2003の得点を等化した結果は,不確か(unclear) なものである(OECD 2012 pp.215-216)。
これはPISA2000とPISA2006との比較においても同様である。PISA2000では読解力問題が129問出題されているが,PISA2003とPISA2006で出題されたのは,この129問のうち同一の28問であり,テストのフレームワークの変更も行われていない。また,PISA2009では再び読解力が主要分野となったため,テストのフレームワークが変更されているが,その目的の一つにはPISA2000のフレームワークと整合性を持たせることが挙げられている(OECD 2009 p31)。
日本の得点の変化はPISAの全体的な傾向と一致している。PISA2000とPISA2003の比較では15か国の得点が有意に変化し,うち10か国が低下,5か国が上昇している。PISA2003とPISA2006の比較では7か国の得点が有意に変化し,うち5か国が低下,2か国が上昇である。そして,PIS2006とPISA2009の比較では14か国の得点が有意に変化し,うち4か国が低下,10か国が上昇となった。PISA2000からPISA2003にかけて得点が低下し,続くPISA2006では変化が小さく,そしてPISA2009では得点が上昇するというのは,PISAの読解力調査の傾向,そしてテスト設計変更の時期と一致するのである。この点は留意しておくべきだろう。
5.5 国際学力調査の問題点
ようやく本章の本題である。ここで説明するのは,ゆとり言説のご神体として崇め奉られているPISAやTIMSSといった国際学力調査は,「科学的に証明された真実」ではないということだ。PISAやTIMSSのように高い信頼性・妥当性を備えた調査でも,その方法論にはいくつかの問題点を抱えており,したがってその結果の解釈には一定の留保が付されなければならない。
PISAやTIMSSの方法論については,教育測定を専門とする研究者からもいくつかの疑義が提出されている。(Ercikan and Koh 2005; Goldstein 2004; Huang 2010; Kreiner and Christensen 2013; Mazzeo and Davier 2009; Wuttke 2007; Xu 2009)。しかし,本稿で行うのは,それらの疑義をもってしてPISAやTIMSSが役立たずの調査であると結論付けることではない。そもそも,これらの問題点は調査の設計者自身にも認識されている(Gebhardt and Adams 2007; Monseur and Berezner 2007; Wu 2009)。
社会的・文化的・経済的背景がまるで異なる国の児童・生徒について,「学力」という曖昧かつ広範な概念を,経時的に調査しようというのである。問題がないわけがない。もとより,何らかの調査や実験が完璧なものであることなどありえない。そこには一定の留保をつける余地が必ず存在する。そして,PISAやTIMSSといった国際学力調査において,その余地は一般の人が思っているよりも少しばかり大きなものであるということだ。たとえば,PISA調査の設計者でもあるGebhardt and Adams(2007) やWu(2009) は次のように述べている。
こうした学力変化の傾向は,研究者や政策立案者,そして報道関係者からの広汎な注目を集めている。しかし,ある国における時系列的な成績の変化が,教育システムの変更によるものなのか,それとも特定の調査手法を使った結果(methodological artefact) であるのかは確認されなければならない。本稿は,傾向推定のための新しい手法について,それらの手法が国ごとに異なる影響を与えていることを注意深く,そして詳細に分析した。その結果が示しているのは,全ての国について共通のアプローチをとること(現行のPISA調査におけるアプローチ) は,傾向を推定する際にミスリーディングをもたらしうるということである(Gebhardt and Adams p318 引用者訳 括弧内は引用者注)。
本稿は,大規模学力調査がどの程度その目的を達成することができているのかを,批判的に検討する。こうした検討が求められるには二つの理由がある。一つ目の理由は,大規模学力調査で使われる方法論のいくつかの仮定が間違っていることが明らかになってきたからだ。これらの誤りは妥当でない結論を導くか,少なくとも,結果には注意を付さなければならない。
二つ目の理由は,メディアの報道によって,政治家を含む公衆の大部分が大規模学力調査の結果を誤って引用したり,利用するからである。最近数か月の間に,政府が国内の学力調査による学校の学力レベルを公表する計画をもっていることを,オーストラリアのメディアが報じた。このような学力調査の結果は,非専門家によって容易に,誤って解釈されるだろう。なぜならば,調査のプロセスは複雑であり,結果の解釈には極めて慎重な態度が要求されるからである(Wu 2009 p8 引用者訳)。
本章の目的は,今引用した指摘を改めて強調することにある。これほどPISAやTIMSSの結果が膨大な文献に引用されながら,その方法論についてほとんど言及がされない現状は常軌を逸している。しかも,その「現状」が10 年以上も続いているのである。(2019年にようやく発売されました!)PISAやTIMSSについて何の批判的検討もせずに引用する人間の一部*9は,これらの調査結果が何か科学的な真理であると認識している節がある。
もちろんそうではない。たとえば実際に,Gebhardt and Adams(2007) やMonseur and Berezner(2007) ではPISA2000からPISA2003にかけての「日本の読解力の著しい低下」にも有意な差は確認できない(Gebhardt and Adams pp318-319;Monseur and Berezner pp.332-333)。また,同様にWu(2009) も日本の読解力低下を事例にして,PISAにおける差異項目機能を説明している。PISAやTIMSSが提示しているのは一つの分析手法とその結果である。唯一絶対の方法などはないし,可能であれば複数の手法を試してみるべきだ。そのためにこそ,PISAやTIMSSでは生徒の解答データをも万人に公開しているのである。
PISAやTIMSSなどの学力調査の結果は,「科学的に証明された真実」ではない。そうではなく,これらの結果は「科学的に検証される推論」として扱われなければならない。検証方法は一つではないし,引き出された推論には更なる検証がまっている。そうでなければ,PISAやTIMSSなどの優れた学力調査すらも学力低下論の箔にしかならないのである。
(ただし,上掲の「PISAの結果まとめ」にも書いているように,表面的な得点推移だけを見ても「ゆとり教育による学力低下」は支持されない。この仮説を支持するのはPISA2003における読解力得点の低下のみであり、本章の内容はほぼ全てこの現象を説明するために費やされている)
5.5.1 等化における誤差
国際学力調査の問題点と一口に言っても,そのすべてに言及することは難しい。テスト問題の開発と構成から,受験者のサンプリング,テストの具体的な実施方法からテストの採点,尺度の作成と等化,テスト得点以外の各種の指標の推定,そして最終的な報告書の作成と,そこから結論を引き出す作業,これらのプロセスの全てにおいて,そのプロセス固有の問題が生じ得る(Wu 2009)。また,測定する能力の一次元性の仮定や,項目困難度の不変性の仮定などを含むIRTモデルの適合度の検討や,DIFの取扱い,等化の方法によって変動する誤差の計算など,学力調査で利用される数理モデル自体の問題点もある。
これらの問題点すべてに言及すること,またその代替案を提案することは筆者の能力を超えている。そこで本稿では,「学力低下」,特にPISA2000とPISA2003の間に見られた「読解力の著しい低下」という現象を中心に,PISA調査における問題点,ひいては国際学力調査の結果を解釈する際の留意点を述べるにとどめたい。すなわち,本稿では「等化における誤差」の問題と,異なる年度のテストを比較する際の「公平性」の問題を取り上げる。まずは等化における誤差の問題である。
5.5.1.2 Linking Errorとは何か
5.4節で説明したように,異なる年度間のPISAやTIMSSの得点が有意に変化したかどうかは
の式を使えば判断することができる。ただし,SEというのは標準誤差(Standard Error) のことである。標準誤差というのは,簡単に言えば標本平均の標準偏差のことだ。たとえば,PISA2003の読解力平均は498点,その標準誤差は3.9となっているが,これはPISA2003の平均得点が3.9点程度は真の平均から典型的にバラつくということを意味している。
標準「誤差」という言葉は,真の平均と推定値との誤差を意味している。たとえば,PISA調査で490点をとったA君と,495点をとったB君の得点差である5点というのは単なる得点のバラつきである。しかし,それらの得点を平均していった498点という値は真の平均に対する推定値となっている。もし,その推定値と真の平均点がずれているのならば,そのずれは単なるバラつきではなく「誤差」ということになる。これが標準誤差の意味である。
さて,PISAやTIMSSのような大標本調査では,標本集団の平均点とその標準誤差が分かれば有意性検定を行うことができる。しかし,TIMSSの場合は上の式で問題はないのだが,PISAの場合には以下のような式が使われている。
見てわかるように,PISA調査における有意差の検定ではLinking Errorというものが分母の√の中に登場している。そのため,PISAでは通常の検定と比較して検定統計量が小さくなり,その分,帰無仮説を棄却する基準は厳しいものとなっている。このLinkingErrorとは一体何なのだろうか。ここでもまた詳細は補遺に譲るとして,結論から言ってしまおう。Linking Errorとは共通項目のサンプリング誤差である。たとえば,以下の表を見てほしい。

これはPISA2000とPISA2003の読解力調査における,共通項目28問のうち最初の7問についての表である。表には,PISA2000のデータのみから計算した項目の困難度と,PISA2003のデータのみから計算した項目の困難度,およびその差を載せてある。また,それぞれの項目困難度は28問の平均困難度が0になるように調整されている。したがって,二つの項目困難度は既に等化されている。
しかし,両者の値は一致していない。もちろん,上記の項目困難度は推定値なので真の困難度と必ずしも一致するわけではない。ただし,その場合は受験者の数を増やしてやれば推定値は安定する。PISAでは10万人以上の人間が受験しているのだから,その推定値の誤差もかなり小さくなっているはずである。しかし,上記の表では,差の絶対値が最も大きなもので0.394ロジットにもなっている。これはPISAのスケールに換算すれば30点以上の差である。
実は,IRTでは「項目困難度の不変性」という仮定を置いているものの,ブックレットの構成や問題が出題される位置,或いはカリキュラムの変更などによって,この仮定は崩れることが知られている(Michaelides and Haertel 2004; Monseur and Berezner 2007;Michaelides 2010)。項目困難度が変化すれば,それによって受験者の成績も変化する。そして,表5.10からもわかるとおり,それぞれの項目困難度の差は,項目ごとに異なっている。「R055Q01」ではPISA2000の受験者にとって「より簡単」な問題になっているし,「R067Q01」では逆に,PISA2000の受験者にとって「より難しい」問題となっている。
つまり,「共通項目の選び方」によって受験者の能力の推定結果が異なってしまうのである。その意味で,Linking Errorとは共通項目のサンプリング誤差を意味している。そのため,いくら受験者の数を増やしても,共通項目の数を増やさない限りLinking Errorは小さくはならない(Michaelides and Haertel 2004)。また,受験者のサンプリングの際に,その代表性に注意しなければならないのと同様に,共通項目のサンプリングもまた,測定したい領域をできるだけ幅広くカバーするように出題されなければならない(Sheehan and Mislevy 1988)。
実際にLinking Errorを計算してみよう。今知りたいのは「困難度の差の平均」という統計量が,平均的にどの程度バラつくかである。つまり,困難度の差の標準誤差である。これがLinking Errorだ。したがって,困難度の差の分散を,共通項目の問題数を
とすると,Linking Errorの計算式は
となる。実際のPISA2000とPISA2003の結果を等化する際のLinking Errorは0.047486/28 = 0.041182 と計算される。つまり,困難度の差の平均は0.041程度,平均的にバラつくということだ。それでは,この困難度の変化を得点に換算してみよう。5.2節で見たように,IRTでは受験者の潜在特性と項目の困難度の差によってのみ正答確率が決定されるため,困難度の変化はそのまま潜在特性の変化であると見なすことができる。現実に得られたデータは変化しないのだから,困難度が変化すれば,そのまま潜在特性も変化するということだ。したがって,PISA2003で0.041ロジット困難度が変化するというのは,PISA2003の受験者の潜在特性が0.041ロジット変化するということでもある。
ただし,ここで得られた0.041ロジットという値を,そのままPISA2003の標準誤差に反映させることはできない。先に説明したように,PISAの得点スケールは平均が500,標準偏差が100である。また,ロジットスケールの基準となるのはPISA2000のスケールなので,0.041ロジットという困難度のバラつきは,1/1.1002*0.041182*100=3.7431となる。1.1002というのはPISA2000の潜在特性(PVs) の標準偏差である。
5.5.2 日本のLinking Error
このLinking Errorは従来のIRTを利用したテストでは無視されることが多かった。しかし,その影響は決して小さなものではない。特に,大規模な学力調査であるほど,Linking Errorを無視することは誤った推論を導く原因になりやすい。先ほども述べたように,Linking Errorは項目のサンプリング誤差であるため,受験者の数を増やしても小さくはならない。一方で,受験者の数を増やせば平均得点の標準誤差は小さくなっていく。もう一度, 式を見てもらえばわかるが,標準誤差が小さければ小さいほど,検定統計量の値は大きくなるのである。それはつまり,有意差が検出されやすくなるということだ。
受験者の数を増やせば増やすほど標準誤差は小さくなっていき,それに従い「有意差がある」と判断される検定統計量も小さくなっていく。しかし,受験者の数を増やしてもLinking Errorの大きさはそのままなので,相対的にその影響が大きくなるのである。帰無仮説が正しいのに,それを棄却してしまう誤りを第一種の誤りと呼ぶが,大規模学力調査でLinking Errorを無視することは,それだけ第一種の誤りを犯す危険性を高くしてしまう。つまり,「平均点に差はない」という仮説が正しいにも関わらず,それを棄却してしまう誤りである。
そこで,PISA調査のような大規模調査では,経年比較を行う際にLinking Errorを使うのである。しかし,Linking Errorには決まった計算方法があるわけではない。たとえば,式はPISA2003では使われていたものの,それ以降の調査では使われていない。PISAで使われているLinking Errorの計算式にはいくつかの問題点があったからだ。PISA2006以降のLinking ErrorはMonseur and Berezner(2007) の指摘によって,クラスターの分散や部分点問題の重みを考慮した計算式を利用している。
Monseur and BereznerはLinking Error について,他にもいくつかの問題点を挙げているが,本稿で注目するのは「国ごとのLinking Error」である。PISAではLinking Errorを計算する際,各国から均等に抽出したサンプルを用いて計算し,その結果得られた一つの値を各国共通のLinking Errorとして用いている。しかし,Linking Errorが各国共通であるという証拠は存在しない。
たとえば,Monseur, Sibbern and Hastedt(2007)はIEAの読解力調査を再分析した結果,Linking Errorが国ごとに大きく異なっていることを報告し,Linking Errorは各国ごとに計算されなければならないとしている。実際に,Monseur and Berezner(2007) はPISA2000とPISA2003における読解力調査のLinkingErrorを計算しているが,それによれば日本の読解力低下にも有意な差は見られない。
先ほども述べたように,Linking Error はカリキュラムの変更によっても発生する。ゆとり言説では,学力低下の原因をもっぱら「ゆとり教育」というカリキュラムの変更に求めているのだから,日本のLinking Errorを計算しておくのは不合理ではないだろう。日本のLinking Errorの値はOECD平均と比較して大きく異なっている可能性がある。実際に計算してみよう。
表5.11は日本の受験者の解答データのみから推定した,PISA2000とPISA2003の読解力問題における項目困難度である。推定にはRのTAMパッケージ(Kiefer et al. 2016)を利用した。IRT モデルは1PLモデル(部分得点モデル) であり,母数の推定法として周辺最尤推定法を用いている。また,各受験者に対するウェイトとしては(W_FSTUWT)を利用した。

表5.11 から計算される日本のLinking Errorはロジットスケールで0.066,PISAスケールで6.0となった。ただし,Linking Errorの計算式はPISA2012のものである(OECD 2014b)。確かにOECD平均よりは大きくなっているが,それでも有意差が消えるほどではない。Monseur and Berezner が報告している日本のLinking Error は13.85となっており2倍以上の値だ。
この違いはテスト項目と国の交互作用(item by coutry interaction) を考慮していないことが原因だと思われる(Monseur and Berezner pp.329-333)。テスト項目と国の交互作用とは,簡単に言えば国によって項目の困難度や成績が変化する度合いが異なるということだ。Monseur and Bereznerはジャックナイフ法と呼ばれる手法を使ってLinking Errorを計算しているが,ジャックナイフ法を使った推定ではある項目(ユニット) を取り除いた時の各国の平均点の変化からLinking Errorを推定する。たとえば,ユニット1を取り除くとOECD平均は4.14 点上昇するのに対し,日本は9.76点上昇する。また,ユニット5を取り除くとOECD平均は0.73 点低下するのに対し,日本は7.72点低下する。
PISAの計算式は,あくまでも,ある国の二つの年度間における共通項目のバラつきを計算しているに過ぎない。そのため,国ごとの項目困難度の違いを取り出すことができないのである。たとえば,他国と比較して日本にとってより難しくなっている問題が共通項目として選ばれたならば,当然日本の成績は低下するだろうし,その逆ならば上昇するだろう。共通項目のバラつきのみから計算されたLinking Errorでは,この違いを取り出すことができないのである。
5.6 差異項目機能
そこで,次はこの国による項目困難度の違いを説明しよう。Linking Errorは等化の手続きにおける誤差を問題としていたが,調査の妥当性を脅かすのは誤差ばかりではない。それがテストバイアスと呼ばれるものである。孫・井上(1995) によれば,テストバイアスは次のように定義される。
テストが測定しようとしている構成概念とは別の要因のために,ある特定の受験者がテストに正答することが,他の受験者と比べて困難になり,その特定の受験者に不利な解釈が行われる”ときテストはバイアスを持つという。そしてテスト全体としてのバイアスをテストバイアス,テストに含まれる項目レベルで現れるバイアスを項目バイアスと呼ぶ。テストのバイアスが問題になるのは,社会経済的地位(socioeconomic status) の差,黒人か白人か,男性か女性かというような,所属集団の違いに起因する系統的差異が見られる場合である。
たとえば,学力調査におけるテストバイアスの一つの典型としては,言語的バイアスが挙げられる。テストで使用される言語によって,特定の母語を持つ受験者集団の成績が不利に解釈されるというバイアスである。テストの実施言語と受験者の母語が違う場合はわかりやすいだろうが,問題を翻訳する際にもバイアスは発生する。たとえば,PISA2000で使われた問題は英語とフランス語では問題文の長さが異なっている。リード文に含まれるワード数は,英語よりもフランス語の方が12%多くなっており,一つのワードに含まれる文字数が英語では4.83文字となっているの対し,フランス語では5.09文字となる。結果として,文字数の総計はフランス語の方が2割弱長くなっているのである。
もちろん,文字数だけではなく,言語概念の相違,用語の使用頻度,文法の複雑さなどによっても言語的バイアスは生じ得る。そのため,ほとんどの国際比較調査では翻訳過程について詳細な設計,分析を行っている。PISA やTIMSS も例外ではない。日本語という特異な(?)言語を母語にする集団の学力を議論したいならば,この点についても知っておくべきだろう。
ただし,テストバイアスの問題は,単にテストの技術的・客観的な問題というよりも,むしろ倫理的・主観的な側面をはらんでいる。たとえば,全体的な「数学の学力」が同じ男女の集団があるとして,特定の領域におけるテストでは女子の成績の方が悪いということがあるかもしれない。「数学の学力」という構成概念とは無関係に,性別によって成績が変化するならば,定義上はテストバイアスということになるが,もしそのテストが特定の領域における優秀な生徒を選抜する目的で使用されるならば,そのテストは妥当なものであるかもしれない(Coel and Moss 1992)。
一方で,こうした選抜自体が「女性に数学はできない・するべきではない」という社会規範を強化する可能性もある。特定領域における学力の差異が,全体的な数学の学力に敷衍されるという意味では,これもテストバイアスと呼べるだろうし,また,その領域についての学習機会や関心が減少することによって,さらに差異が拡大されるようなことがあれば社会的に対応すべき問題にもなる。これは,男女に見られる能力の差異が,仮に男女の生理的機構に負っているとした場合も同様である。集団間に見られる系統的差異がテストバイアスであるかどうか,或いはそれにどう対処すべきかという問題は,人間の倫理的・主観的判断を必要とするのである。
そのため「バイアス」という言葉に代わり,現在ではあるテスト・テスト項目に対する系統的集団差一般を意味する「差異項目機能(Differential Item Functioning=DIF) という,より価値中立的な用語が使われている。DIF はバイアスのようにテストやテスト項目に見られる集団差が「構成概念とは無関係な原因によって生じる不公正なもの」であるかは考慮しない。ただ,あるテスト・テスト項目に対する系統的な集団間の差をDIF と表現するのである。したがって,バイアスが存在するときは必ずDIF が存在するが,DIF が存在するからといってバイアスが存在するとは限らない。あるDIF がテストバイアス・項目バイアスであるかどうかは,そのテストが実施,解釈される文脈に依存する。
DIFがこのように定義されると,前節の「等化の際の項目母数の変化」もDIFの一つであると思われるかもしれない。もちろんそうなのだが,Linking Errorがあくまでもサンプリング誤差の問題であるのに対し,DIFはバイアスの問題である。そのため共通項目の数を増やす,或いは共通項目の代表性を高くするという比較的単純な作業によってLinking Errorの問題が解決するのに対し,DIFはそうした単純な作業によって取り除くことはできない。
5.6.1 PISA におけるDIF
そのため,DIFの問題は多くの学力調査,特に文化的・社会的・経済的差異の大きい国際比較調査においては深刻な問題となりうる。もちろん,PISAも例外ではない。多くの研究者はPISAにおけるDIFの問題を理解しているが,その取扱い方は研究者によっても見解が異なる(Kreiner 2012)。最も単純な方法はDIF項目をテストから排除してしまうことだ。たとえば,PISAでは最終的な項目困難度を計算する前に,各国ごとの項目困難度を計算し,その結果不適切とされた項目("dodgy" item) は当該の国から除外されることになる(Kirsh et al. 2002)。
一方で,PISA設計者の一人でもあるAdams(2007) はitem-splittingという手法を使うことを提案している。たとえば,ある国においてのみ特異的に機能する項目(DIF) が存在するとき,その項目を排除するのではなく別の項目が与えられたと解釈するのである。理屈から言えば,この手法ではDIFから自由になることができる。その意味でこの手法はfreeingとも呼ばれる。実際にTIMSSでは,項目がテストの中に現れる位置によって項目の特性が変化してしまうため,それぞれを別の項目と見なしている(TIMSS 2003 p.264)
或いは,より積極的にDIFを活用しようと考える研究者もいる。たとえば,Zwister et al.(2015) は,DIFをテストの妥当性を脅かすものではなく,「それぞれの国の多様性や経時的なダイナミクスを反映した興味深いテストの成果物」として捉えることを提案している。つまり,DIFを単に問題のあるのもとして排除するのではなく,それぞれの国の社会経済的な環境や文化的背景,経時的な変化などの多様性を含んだ貴重な情報として活用しようという考えである。Zwisterは,DIFのうち,テストの妥当性を脅かすのは構成概念に関連しないDIF(construct unrelatd DIF) であることを強調している。
それぞれの考え方があるということは,どの考え方にも問題があるということだ。DIFを排除したり,別の項目に読み替える方法では,結局のところその基準が明らかにはならない。すべての項目母数が正確に一致することはないのだから,どこまでが問題のあるDIF項目で,どこまでが問題のない妥当なテスト項目であるのかを判断することは難しい。加えて,DIFを活用しようといっても,DIFをそのままにテストの結果を計算するのは危険である。テストの結果を受け取る一般人の大多数はそんなことに興味がないからだ。DIFがあろうとなかろうと,平均点が500点ならばどこまでいっても500点であり,それは未来永劫変わらない。
また,あるDIFが構成概念に関連しているのか,いないのかという判断はそれほど容易なものではない。たとえば,PISAの読解力調査では4回の調査の全ての国において,男子よりも女子の成績の方が高い。極めて強固な系統的集団差が見られる。この現象を一言で説明するのは難しいだろう。おそらくは複数の要因が考えられるはずだ。ここまで明白な差が見られるということは,構成概念に関連するDIFと構成概念に関連しないDIFの両方を含んでいる可能性がある。
5.6.2 日本のDIF
DIFの取扱い方が研究者によって異なると言っても,それが「公平性」という観点から問題が多いのは確かである。そこで,本節ではPISA調査における日本のDIFについて説明しよう。国際比較調査におけるDIFは,ある国と別の国の結果を比較する際の公平性が問題とされることが多いが,ここで焦点を当てるのはPISA2000の日本の読解力得点と,PISA2003の日本の読解力得点を比較する際の公平性である。
PISA調査の設計者でもあるWu(2009) は,PISA2003における日本の読解力低下を例にして,PISA調査におけるDIFの存在を指摘している。図5.11は,PISA2000におけるOECD参加国の項目困難度と,日本の項目困難度をプロットしたものである。項目母数の推定方法は前節と同様だが,OECD27か国のデータは国によって受験者の数が異なるため,それぞれの国に均等の重みをつけて計算した(OECD 2005 p.132)。

見てわかるように,日本の項目困難度とOECDの項目困難度はおおむね直線に近づいている。しかし,個々の項目を見ていくと,日本の困難度とOECDの困難度が,著しく異なる項目が存在していることがわかる。たとえば,散布図の第2象限にはOECDの困難度が-1,日本の困難度が1となっている項目が存在している。2ロジットの差というのはPISAスケールならば200点に相当する差である。もはや別の項目だ。また,1ロジット以上の差を示す項目は129問のうち10問存在している。そのうち5問は日本にとってより難しい問題,5問はより簡単な問題である。これらの問題は明らかなDIF項目だ。
PISA2000では,読解力問題129問のうち,日本にとって著しく難しい,或いは簡単な問題が含まれている。そして,PISA2003の読解力問題28問は,その129問の中から選ばれているのである。このことは,PISA2003において共通項目として何が選ばれるのかによって,日本の成績が大きく変動することを示唆している。Wuによれば,PISA2003で選ばれた共通項目は日本にとって,平均して0.08ロジット難しいものになっており,PISAのスケールに変換すれば約8点に相当する(Wu 2009 p.25)。
筆者が推定に使ったOECDサンプルと,Wuが使ったと思われるOECDサンプルは若干異なるため,正確に同じ数字になるわけではないが,筆者の推定でもPISA2003では日本にとって,平均して0.082ロジット難しい問題が出題されていた。PISAスケールに変換して7.5点に相当する差である。仮に,PISA2000におけるDIFの影響が,PISA2003でも同様に影響するならば,日本の平均点はそのまま7.5点程上昇するということだ*10。
これはあながち無理な仮定でもない。というのも,国際比較調査におけるDIFは地域的・言語的・文化的区分によって,ある程度固定的で一貫した傾向が見られるからだ。たとえば,DIFの大きさを測る指標としては,因子分析による各国の共通性,各国の困難度と全体の平均困難度の差の絶対値といったものを利用することができる(Grisay et al 2007; Grisay et al 2009)。
各国の共通性とはすなわち各国の項目困難度の分散うち共通因子によって説明される割合を意味している。共通性が低いほど,その国独自の要因(DIFなど) によって項目困難度が変化しているということだ。図5.12は,Grisay et al.(2009)が計算したPISA2000の読解力問題における各国の言語ごとの共通性である。

一見してわかるのは非インドヨーロッパ語族でその共通性が低くなっていることだ。ここではインドネシア語(IND),中国語(CHI),フィンランド語(FIN),ヘブライ語(HEB),ハンガリー語(HUN),日本語(JAP),韓国語(KOR),トルコ語(TUR),タイ語(THA)が非インドヨーロッパ語族にあたる。中でもインドネシア,香港,日本,韓国,タイといったアジア諸国の共通性の低さが鮮明になっている。
この傾向は各国の困難度と全体の平均困難度の差においても同様にみられる。図5.13もGrisay et al(2009) が計算したPISA2000の読解力問題における各国の困難度と全体の平均困難度との差の絶対値である。

こちらでも同様に,非インドヨーロッパ語族では概して差の絶対値は大きくなっている。その中でもアジア諸国の差が大きいという傾向も変わらない。いずれの指標においても,地域或いは言語による差異がある程度一貫しているという傾向,また特にアジア諸国とそれ以外の地域による差異が大きいという傾向には注意しなければならない。特に「読解力」という言語能力と密接に結び付いた能力を測定するならばなおさらのことだ。問題の性質が全ての国において同様であるという仮定はテストを実施するためには必要かもしれないが,結果を解釈する段階においてもその仮定を維持する必要はない。
それでは最後に,Linking ErrorとDIFを考慮した有意性検定を行ってみよう。日本のLinking Errorは前節で計算したように6.0である。また,DIFを考慮するとPISA2003では日本の平均点は7.5点に相当する得点の変化が見られる。したがって検定統計量は
となり,有意水準0.05の場合は有意な差が見られない。ああよかった…という話ではない。これは強引な結論である。仮にPISA2000で確認されたDIFが地理的・言語的・文化的差異によって完全に説明されるのであれば,この結果にも一定の妥当性はあるが,実際には各国のカリキュラムの違いに起因するDIFもある程度は含まれているはずだ。したがって,PISA2000におけるDIFによる得点の補正を,Linking Errorを使って検定するのは「カリキュラムの変更による得点の変化」が(一部) 二重に計算されるため,保守的な検定となっている可能性がある(逆の可能性もある)。その上,1.877というのはギリギリもいいところである。
しかし,冒頭でも述べたように,本節で説明し,かつ強調したいのはPISAやTIMSSなどの調査結果は,「科学的に証明された真実」ではないということだ。そのために,特に「学力低下」という観点から,二つの時点の調査結果を等化する際に発生する誤差と,異なる社会的背景をもつ集団にみられるバイアスについて別々に分けて説明したのである。先に引用したMonseur and Berezner(2007) やGebhardt and Adams(2007) のように,日本の有意差をもっと「綺麗に消す」方法もあるが,本稿の趣旨ではない。
結語
おわり。ここまで一瞬でスクロールした人に念のため屡述すると,PISA調査の表面的な得点推移だけを見ても「ゆとり教育による学力低下」説は支持されない。この仮説を支持するのはPISA2003における読解力得点の低下のみであり、本章の長大な内容はほぼ全てこの現象を説明するために費やされている。ただし,PISA2015以降の調査報告書では,PISA2000-2006のサイクルにおける日本の読解力低下について直々に注釈が付されており,本章の内容が理解できなかった人はそれを読んで納得しても良い。
引用・参考文献
[1] 川口俊明 2014 「国際学力調査からみる日本の学力の変化」 福岡教育大学紀要 第63号
[2] 豊田秀樹 2002 「項目反応理論<入門編>―テストと測定の科学―」朝倉書店
[3] 日本テスト学会 2010 「見直そう,テストを支える基本の技術と教育」金子書房
[4] 南風原朝和 1980 Equating Logistic Ability Scales by a Weighted Least Squares Method, Japanese Psychological Research 22(3), pp.144-149
[5] 文部科学省 2013 「国際成人力調査(PIAAC) 調査結果の概要」 http://www.mext.go.jp/b_menu/toukei/data/Others/__icsFiles/afieldfile/2013/11/07/1287165_1.pdf
[6] Belia, S., Fidler, F., Williams, J., & Cummin, G. 2005. Researchers misunderstand condence intervals and standard error bars., Psychol Methods. 2005 Dec;10(4):389-96.
[7] Cumming, G., & Finch, S. 2005. Inference by Eye Condence Intervals and How to Read Pictures of Data, American Psychologist, Vol. 60, No. 2, 170 180
[8] Cumming, G., Fidler, F., & Vaux, L.D. 2007. Error bars in experimental biology, The Journal of Cell Biology. 2007 Apr 9; 177(1): 711.
[9] Ercikan, K., & Koh, K. 2005. Examining theconstruct comparability of the English andFrench versions of TIMSS, InternationalJournal of Testing, 5(1), 23-35.
[10] Goldstein, H. 2004. International comparisons of student attainment:some issues arising from the PISA study. Assessment in Education Principles Policy and Practice 11(3) September 2004
[11] Gebhardt, E., & Adams, J.R. 2007. The Infuence of Equating Methodology on Reported Trends in PISA, JOURNAL OF APPLIED MEASUREMENT, 8(3), 305-322
[12] Grisay, A., de Jong, J.H., Gebhardt, E., Berezner, A., & Halleux-Monseur, B. 2007. Translation equivalence across PISA countries. Journal of Applied Measurement, 8(3) 249266.
[13] Grisay, A., Gonzales, E., & Monseur, C. 2009. Equivalence of item difficulties across national versions of the PIRLS and PISA reading assessments. von Davier, Matthias; Hastedt, Dirk (eds.) IERI Monograph Series: Issues and Methodologies in Large-Scale Assessments: Volume 2. 2009, p63-83
[14] Head, M.L., Holman, L., Lanfer, R., Kahn, A.T., Jennions, M.D. 2015. The Extent and Consequences of P-Hacking in Science. PLoS Biol 13, e1002106
[15] Huang, X. 2010. Differential Item Functioning:The Consequence of Language, Curriculum, or Culture?, Graduate School of Education of the University of California, Berkeley.
[16] Kirsc, I., de Jong. J.H., Lafontaine, D., McQueen, J., & Monseur, C. 2002. Reading for change. Performance and Engagement across countries. Results from PISA 2000, OECD
[17] Kreiner, S., & Christensen, B.K. 2013. Analyses of Model Fit and Robustness. A New Look at the PISA Scaling Model Underlying Ranking of Countries According to Reading Literacy Psychometrika April 2014, Volume 79, Issue 2, pp 210-231
[18] Mazzeo, J.,& von Davier, M. 2009. Review of the Programme for International Student Assessment (PISA) test design: Recommendations for fostering stability in assessment results. Retrieved July, 2009, from http://edsurveys.rti.org/PISA.
[19] Michaelides, M.P. & Haertel, E.H. 2004. Sampling of common items: An unrecognized source of error in test equatingTechnical Report. Los Angeles: Center for the Study of Evaluation and National Center for Reserch on Evaluation, Standards, and Student Testing.
[20] Monseur, C. & Berezner, A. 2007. The Computation of Equating Errors in International Surveys in Education, JOURNAL OF APPLIED MEASUREMENT, 8(3), 323-335
[21] Mullis, I.V.S., Martin, M.O., Smith, T.A., Garden, R.A., Gregory, K.D., Gonzalez, E.J., Chrostowski, S.J., & O'Connor, K.M. 2003. TIMSS Assessment Frameworks and Specications 2003, TIMSS & PIRLSInternational Study Center.
[22] OECD, 2003, PISA2003 Assessment Framework, OECD
[23] OECD, 2005, PISA 2003 Data Analysis Manual, OECD
[24] OECD, 2007, PISAT M 2006 Science Competencies for Tomorrow’s World Volume 1 Analysis, OECD
[25] OECD, 2012, PISA 2009 Technical Report, OECD
[26] OECD, 2014a, PISA 2012 Results: Creative Problem Solving Students’ skills in tackling real-life problems Volume V, OECD
[27] OECD, 2014b, PISA 2012 Technical Report, OECD
[28] Sheehan, K.M., & Mislevy, R.J. 1988. Some consequences of the uncertainty in IRT linking procedures.(Report No: ETS-RR-88-38-ONR) Princeton, NJ: Education Testing Service.
[29] Stewart, W. 2013. Is Pisa fundamentally awed?, TES, 26th July 2013 https://www.tes.com/news/tes-archive/tes-publication/pisa-fundamentally-flawed
[30] Stocking, M., & Lord, F.M. 1983. Developing a common metric in item response theory., Applied Psychological Measurement, 7, pp.207-210.
[31] Wasserstein, R., & Lazar, N. 2016. The ASA's statement on p-values: context, process, and purpose, The American Statistician Volume 70, Issue 2, 2016
[32] Wu, M. 2009. Issues in Large-scale Assessments, Keynote address presented at PROMS 2009, July 28-30, 2009, Hong Kong.
[33] Wuttke, J. 2007. Uncertainty and Bias in PISA, PISA ACCORDING TO PISA. DOES PISA KEEP WHAT IT PROMISES, Hopmann, Brinek, Retzl, eds., pp.241-263, Wien, 2007
[34] Xu, X, & Davier, V.M. 2010. Linking Errors in Trend Estimation in Large-Scale Surveys: A Case Study, ETS Research Report Series, Volume 2010, p.112

*1:図5.1ではグラフ作成の都合上,関連領域の下に認知的領域を置いているが,実際にはそれぞれの内容領域について,各認知的領域を測定する問題が出題される。そのため,各関連領域についてすべての認知的領域に対応した問題が出題されるわけではない。
*2:後で確認するが,PISAではそもそも数学的リテラシー得点の有意な低下は確認できない。
*3:つまり,学力が低い集団にとっては項目aよりも項目bが難しくなっているが,学力の高い集団では項目aの方が難しいといったことである。補遺参照。
*4:説明のためこの式は簡略化している。詳細は補遺を参照。
*5:その場合にも得点が割り当てられることには留意
*6:これは基準となるテストの得点に限られる。後述。
*7:実際はテスト得点の標準誤差と呼ぶ。後述。
*8:2群の平均の差を検定する場合,本来は帰無仮説として,「二つの平均値が同一の母集団から得られた」という仮説と,「2群は平均値の等しい母集団である」という二つの仮説がありうる。前者が(2群の母集団の)等分散性の仮定を必要とするのに対し,後者は必要としない。実際に検定をする場面では,等分散性が必要となるt検定を使うことが多いため,帰無仮説としては前者の方が正確ということになるが,PISA調査のように,大標本調査の場合には正規検定を使うことができるため,等分散性の仮定は必要ない。また,同じ国の子どもの学力の分布が数年で著しく変化するということも考えられないので,もとより等分散性は仮定できる。そのため,どちらの仮説を採用しても問題はないが,ここでは分かりやすいように後者の仮説,つまり「PISA2000とPISA2003の平均得点は同じ」という仮説を採用している。
*9:ハッキリ言って全部
*10:ただし,これは各項目の困難度が一律に変化した場合である。実際には各項目ごとに困難度が変化するため,数値にはわずかな違いが出る。詳細は補遺参照。

")


")